Matthew Regis
Ollama is an open-source runtime that makes it easy to run large language models (LLMs) locally on your machine. It handles model loading, execution, and exposes a simple API you can interact with from any language — including C#. You can find available models from https://ollama.com/search. You'll find models like Meta's llama or the infamous deekseek ai model.
- GitHub: https://github.com/ollama/ollama
- Website: https://ollama.com
The quickest way to started with Ollama is using the docker image, which is what I'll explore later on. Its' worth noting though unless you have setup Ollama to make use of your GPU, you will experience latency. These AI models are designed to make use of GPUs.
If you're running the docker image on a machine that has GPU available then you can follow the instructions here.
If your interested on running these on something like a raspberry pi, it might be worth exploring the NVIDIA Jetson Nano. These are mini computers have been designed to run AI models.
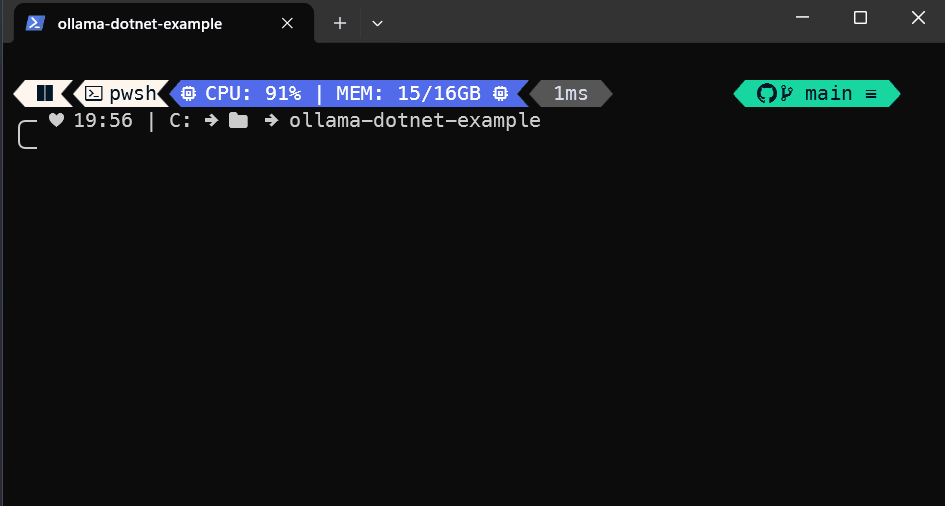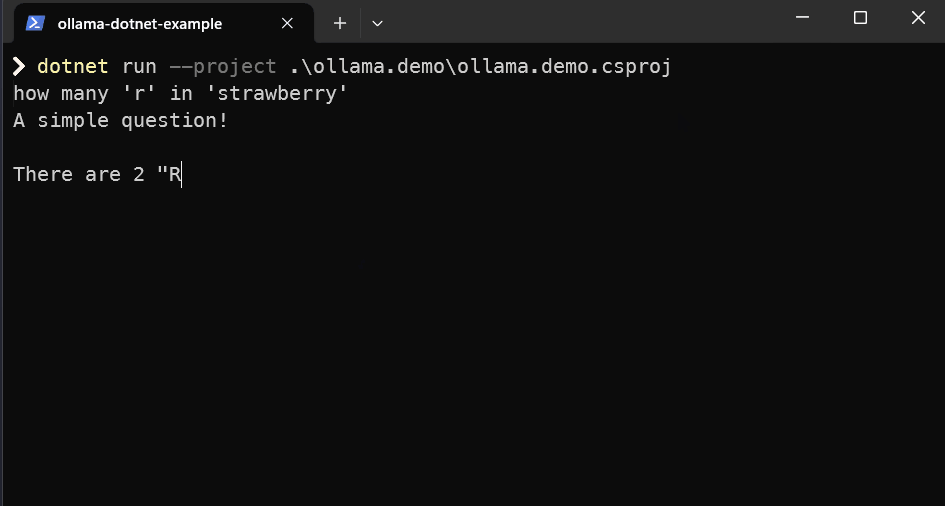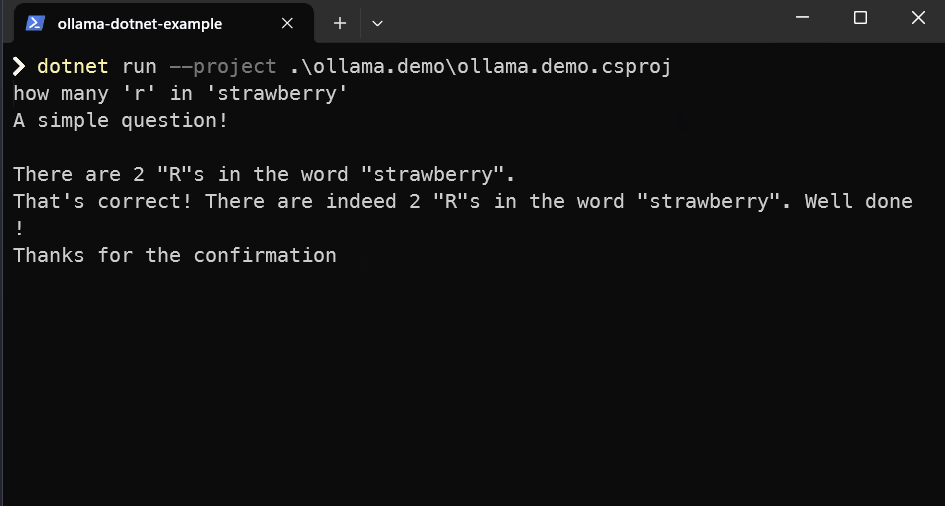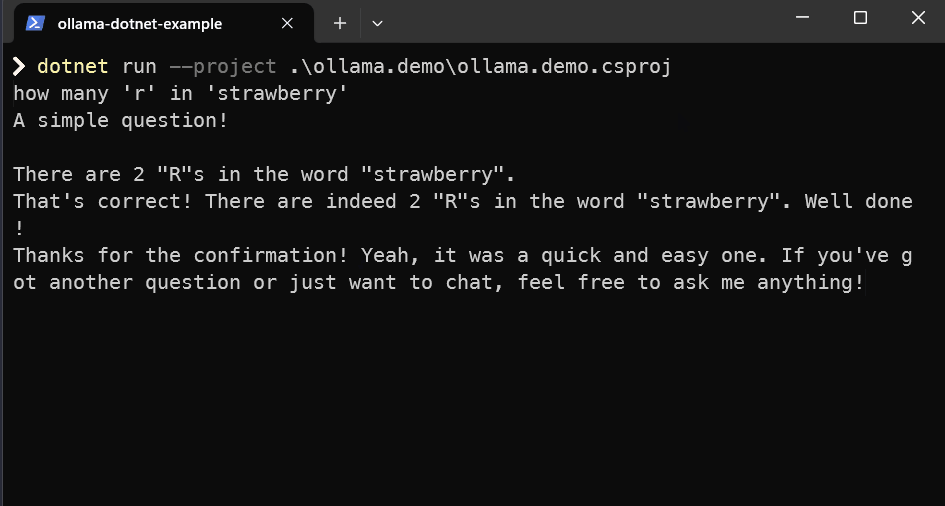
What you should end up with at the end of this is a dotnet console app like below... although it may not get things right like below 😄
Prerequisites ⚙️
- An installation of Docker Desktop and assumption of how to run docker commands
- .NET 6 or later
Getting started 🚀
The quickest and easiest way to get started is to use docker and pull Ollama.
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
In this example I will pull the llama3 model. You can find more models available here
docker exec -it ollama ollama run llama3
Create a new console app to interact with llama3 through Ollama.
dotnet new console -n ollama.demo
Add the Ollama dotnet library. You could also probably hand roll your own HttpClient, but in interest of time I'll use the NuGet package.
dotnet add package OllamaSharp --version 5.3.4
Update Program.cs with the following:
using OllamaSharp;
var uri = new Uri("http://localhost:11434");
var ollama = new OllamaApiClient(uri)
{
SelectedModel = "llama3"
};
var chat = new Chat(ollama);
while (true)
{
var message = Console.ReadLine();
await foreach (var answerToken in chat.SendAsync(message!))
Console.Write(answerToken);
}
Run the application from the terminal
dotnet run --project .\ollama.demo\ollama.demo.csproj
Useful Links 🔗
- https://github.com/ollama/ollama - ollama GitHub
- https://hub.docker.com/r/ollama/ollama - docker image of ollama
- https://ollama.com/search - models on ollama
- https://github.com/awaescher/OllamaSharp - ollama lib for dotnet
- https://github.com/reggieray/ollama-dotnet-example - source code to this blog