Matthew Regis
Introduction
This is part of a multi part blog post where I go over an example event-driven microservice project, using a fictional payment processor named Regis Pay as an example. To see the previous blog post click this link on Event Sourcing.
Overview
In this blog post I wanted to do a architecture overview and how everything combines together after having gone over the transactional outbox pattern and event sourcing pattern respectively as both are important patterns that warranted their own focus.
I'll also mention some points that have not been touched upon in the example project, mainly because I have not added any code for it, but thought it's worth mentioning.
Architecture
The diagram below shows the overall structure and how each component interacts with each other.
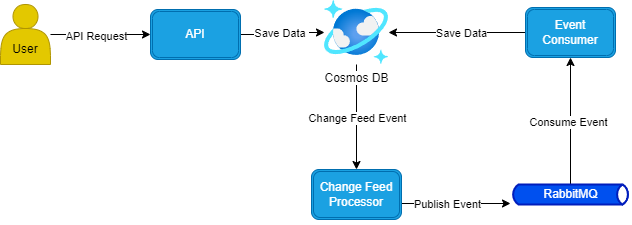
The diagram below takes this further by showing how a payment would flow through the architecture.

Resiliency
In the example code I use RabbitMQ, the main reason for this is because I wanted the whole solution to run locally. In a ideal world though I would have wanted to use Azure Service Bus locally to keep technologies consistent with Azure, but sadly this wasn't option for Azure Service Bus. Having said that though, through the use of MassTransit if you wanted too, you could easily run this with Azure Service Bus if you tweak the code.
The main point I wanted to make is that using these message brokers such as RabbitMQ or Azure Service Bus gives you resiliency out the box if configured correctly. Many message brokers have a concept of Dead Letters, this is when a message could not be successfully consumed which could be as a result of many reasons such as time-outs, transient issues or critical issues.
I haven't coded this into the example, but the main idea around it is to have some retry policy that makes sense to your context to handle:
- Transient Errors - An example of this happening could be because an API dependency you are using had a failed deployment and it's returning a Internal Server Error, that would get automatically resolved because of a rollback or a fix forward. The qualities that I would typically see of transient errors are:
- Max retry limit
- Backoff policy
- Logging
- Permanent Errors - If you know something isn't going to work then fail fast and have alerting in place to identify when this occurs. Qualities you'd see with permanent errors are:
- Dead lettering
- Alerting
- Ability to replay messages
Idempotence is also a key consideration when thinking about resiliency. For example is it safe to retry the payment initiated event? would this create the payment multiple times or is the third party system idempotent or should we build this into the system. These are some questions I would ask and the answers would depend on your context.
Integration
In a microservice world you might have multiple components that want to integrate with your component. This is made easy through the use of a message broker, integration events published to a topic of which you might also be a subscriber could also be offered to other components.
In the diagram above I added a note "Consume integration events" this could also be a way in for other components to consume the same event integration event.
Scale
I haven't coded this into the example, but because of the way the solution was architected this could be deployed to Kubernetes or Azure Service Fabric with the ability to scale each component vertically or horizontally as needed. For example if you have to cater to lots of API requests, but you don't have concerns of backend processing you could focus on scaling the API component.